Large Language Models have revolutionized code generation and execution tasks, significantly enhancing development efficiency, lowering barriers to coding, and improving code quality. However, existing frameworks struggle to perform well in complex development cycles with various industry standards that heavily rely on coordination and communication. Additionally, we need more suitable data to align the system, especially in highly interactive scenarios.
To address these issues, we developed a multi-agent collaboration system that treats humans and LLMs as agents, enabling them to interact. This system facilitates error correction before execution and allows adjustments based on existing code. To enhance code performance and execution efficiency, we defined meta-agents and meta-tools, abstracting user instructions into modular tasks that can be executed in parallel. We aligned the system by leveraging the data we obtained to achieve continuous self-improvement. Finally, we developed an efficient meta-agent collaboration system integrating interactive code generation and parallelizable system execution feedback, which we call ALICE.
ALICE has several applications:
Currently, we focus on code generation and execution in game engines like Unity, as they provide a fully controllable, observable, and modular virtual environment. We plan to generalize this system to broader domains in the future.
We propose an efficient meta-agent collaboration framework named ALICE, designed to follow user instructions through active communication, aligning with their intentions, and generating code based on continuous feedback and interaction. This section will discuss 3 main components of ALICE, Controller LLM, Intent LLM and Execution LLM.
ALICE distinguishes from traditional multi-agent collaboration frameworks by its allowance of dynamic creation and management of agents and tools.
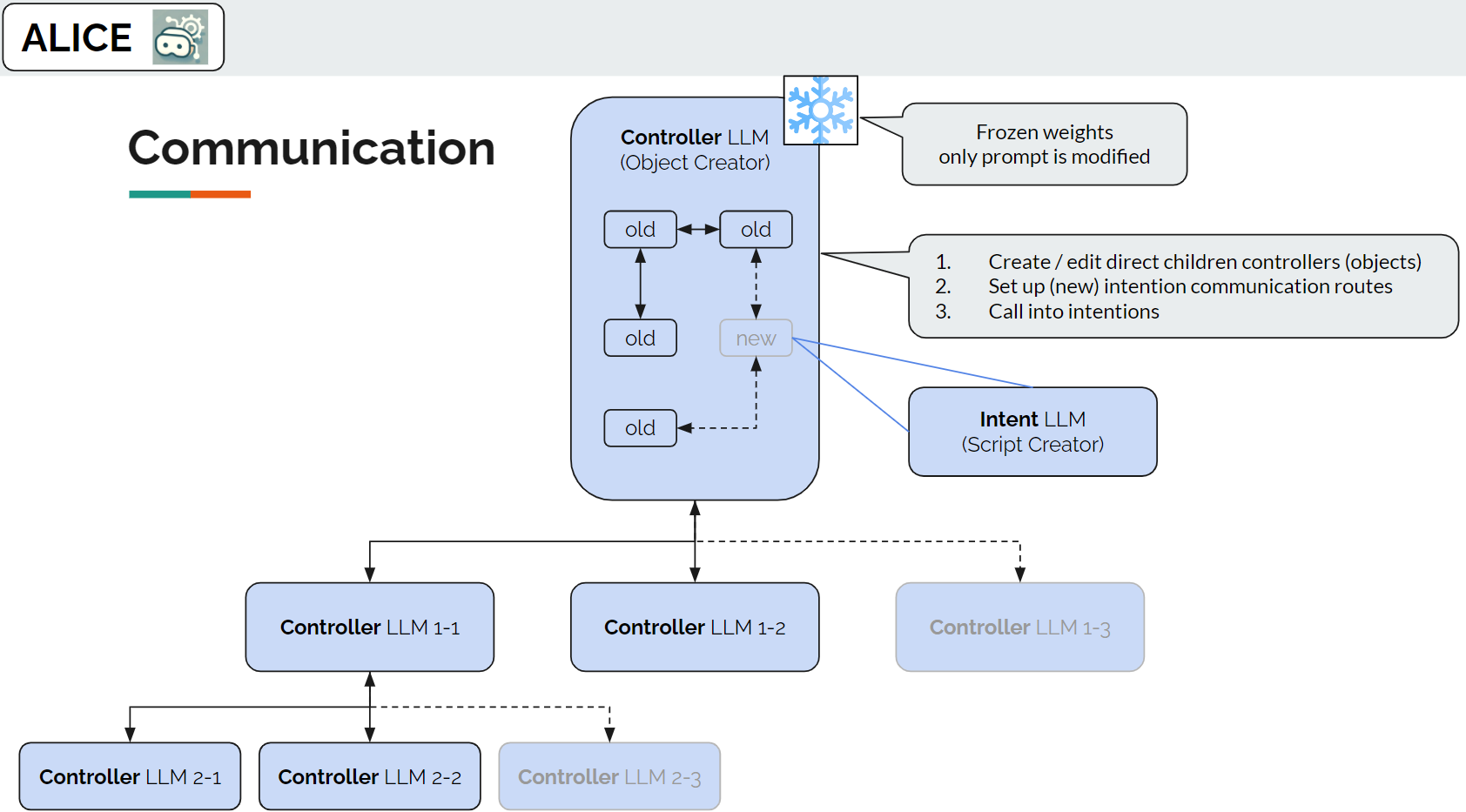
We setup a controller LLM with the following fixed operations that manage and interact with a suite of intention LLMs, which can be treated as general LLM agents seen in other frameworks.
This configuration enables the controller LLM to act as the creator of other LLMs, which are essentially LLMs with different instruction prompts. Note that the LLMs it creates are also controllers, i.e. they are equipped with the same 3 operations as their parent controller. The controller LLMs do not do any task; instead, they are communicators with other LLMs and the user.
The following figure gives an example of a Controller LLM.
Intent LLMs are named by their nature of following personalized instructions. Each intent LLM is in charge of all the changes of a special code script, that is called a game component, and an execution LLM.
Game Components
Physic engines usually use a component-based architecture, where
each object in the virtual scene can have various components attached to them that perform
operations in parallel. This modular approach allows developers to compose behavior and
properties by attaching different components to objects, such as renderers, scripts, colliders,
or custom components. A game component is a script that an object can have, for example, a
Terrain.cs script defines how an area of geographic structure is rendered, containing methods
(tools) to create trees, grass and mountains. It can be treated as a class of any API library.
As such, we attach a fine-tunable LLM to each API script we care about, by reading its
class documentation in its declaration, attribute getter and setter, to each method (function)
example usage as part of the model prompt.
The intent LLM is equipped with the following operations.
This setup allows the intent LLM to be a creator for code scripts, especially higher-level code from existing code. This design is analagous to the idea of skill library in Voyager (Wang et al., 2023), where the agent is prompted to adapt new tools that incorporates existing atomic tools.
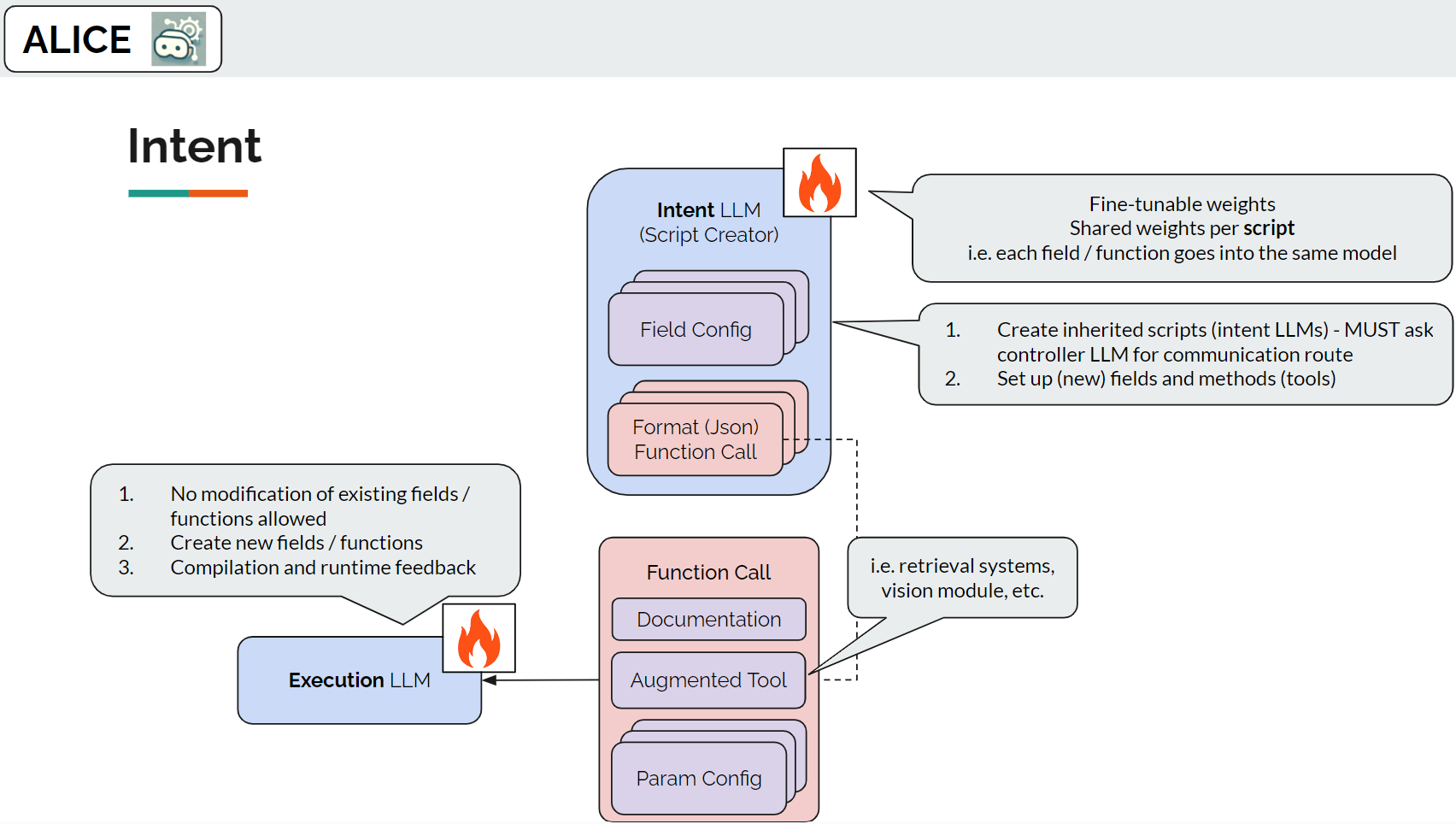
An execution LLM controls how an API script should be used when receiving user instructions related to its component update, augmented with tools (functions) written in the given script. In practice, we give it the header file (Terrain.h).
Different from a general instruction-tuned code generation model, an interactive code execution LLM generates code via multi-turn conversation feedback from the game engine and the user. As we modularize the API separation, each execution model can criticize the given instruction for its game component by asking back the parent intent LLM for clarification in code execution with unknown parameters. For example, to add trees in a Terrain component, the user might want to further specify the tree density and range requirements before letting the model proceed with the code generation task. We collect feedback from each execution LLM and send them to the upper level to wait for the user or the controller with a broader knowledge about the APIs to respond.
The interactive code execution LLM is equipped with the operations to generate code, incorporating feedback from the tools it is given from the intent LLM, or report the final code it writes that is ready for execution.
A big advantage of the ALICE system is that it is orthogonal to popular agent strategies by its nature of design. The operations that are primarily equipped to each LLM component can be boosted by planning ahead, reasoning through, self-critized, and virtually executed as actions to better follow user instructions.
To use ReAct (Yao et al., 2023), for example, the intent LLM can be equipped with the following action space (tools): reasoning trace/thought, retrieving relevant targets/components in the simulated environment, communication with the user, and finally, answering the question. Essentially, at each trace stage, the agent can either make a reasoning thought, generate code after retrieving relevant components to the task at hand, communicate with the user to learn further specifications, or provide a final answer. The tools it have is controlled by its upper-level controller LLM for efficiency and flexibility.
ALICE example input and output. The ALICE (icon) result from left to right shows the result of GPT-3.5 before, as fine-tuning progress, and after alignment. The ground truth is not included in the training.

